Build an AI assistant for aircraft maintenance
Create an AI assistant to parse data and retrieve complex private information from PDF documents. Learn to use RAG patterns with a powerful LLM (like Llama2), and create an effective user interface for data utilization.
4.2 (11 Reviews)

Language
- English
Topic
- Artificial Intelligence
Enrollment Count
- 63
Skills You Will Learn
- Python, LLM, Generative AI, RAG, Vector Database
Offered By
- IBMSkillsNetwork
Estimated Effort
- 45 min
Platform
- SkillsNetwork
Last Update
- May 17, 2024
This approach is beneficial for companies with vast repositories of information. By integrating AI, they can efficiently and quickly access and communicate with their knowledge databases. This information could range from text-based customer conversations to sales data described in CSV formats.
The information processing pipeline of the documents processing and feeding to LLM is shown in the following image.
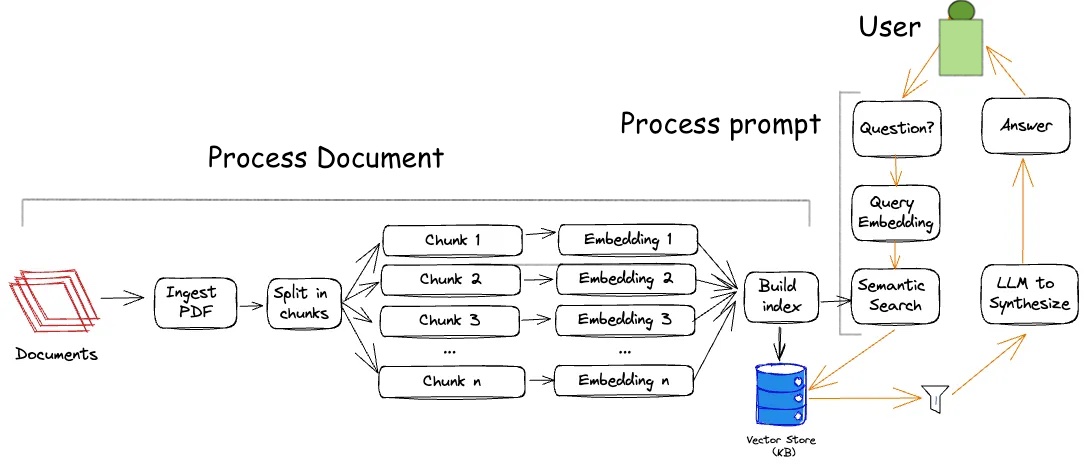 Information processing pipeline
Information processing pipeline
A look at the project ahead
- Vector database construction: Establish a database that manages data as vectors, optimizing it for advanced machine learning and natural language processing applications. This database will serve as the foundation for the AI assistant to retrieve and interpret large volumes of document-based information efficiently.
- AI-assisted information retrieval: Develop an AI assistant that can parse through extensive repositories of PDF documents, enabling quick and contextually accurate retrieval of information. This system will enhance the capability of companies to interact with and utilize their vast data stores, such as technical manuals, sales records, and customer correspondence.
- Contextual understanding and response: Implement a language learning model that uses the vector database to understand queries in natural language and provide precise answers. This involves processing the text data to identify and understand the context, enabling the AI to deliver responses that are tailored to the specific knowledge encapsulated in the documents.
- User interaction interface: Create a user-friendly interface, such as a Gradio chatbot, that allows users to interact with the AI assistant. This interface will enable users to ask questions and receive answers derived from the content within the PDF documents, providing an effective tool for knowledge discovery and customer service.
What You'll Need
Language
- English
Topic
- Artificial Intelligence
Enrollment Count
- 63
Skills You Will Learn
- Python, LLM, Generative AI, RAG, Vector Database
Offered By
- IBMSkillsNetwork
Estimated Effort
- 45 min
Platform
- SkillsNetwork
Last Update
- May 17, 2024
Instructors
Sina Nazeri
Data Scientist at IBM
I am grateful to have had the opportunity to work as a Research Associate, Ph.D., and IBM Data Scientist. Through my work, I have gained experience in unraveling complex data structures to extract insights and provide valuable guidance.
Read moreContributors
Wojciech "Victor" Fulmyk
Data Scientist at IBM
As a data scientist at the Ecosystems Skills Network at IBM and a Ph.D. candidate in Economics at the University of Calgary, I bring a wealth of experience in unraveling complex problems through the lens of data. What sets me apart is my ability to seamlessly merge technical expertise with effective communication, translating intricate data findings into actionable insights for stakeholders at all levels. From modeling to storytelling, I bring a holistic approach to data science. Leveraging machine learning algorithms, I construct predictive models tailored to both real-world challenges as well as old, well-understood problems. My knack for data-driven storytelling ensures that the insights uncovered resonate with both technical and non-technical audiences. Open to collaboration, I'm eager to take on new challenges and contribute to transformative data-driven endeavors. Whether you seek to extract insights, enhance predictive models, or explore untapped potential within your datasets, I'm here to help. Feel free to connect to me via my LinkedIn profile. Let's learn from each other!
Read moreKang Wang
Data Scientist
I am a Data Scientist in the IBM. I am also a PhD Candidate in the University of Waterloo.
Read more