Group your data: Clustering using Python and scikit-learn
BeginnerGuided Project
Explore machine learning clustering methods with Python and scikit-learn, including K-means, hierarchical, and DBSCAN, and learn cluster visualization techniques using the Plotly and Seaborn libraries. This course equips you with the skills to uncover patterns in data and make insightful discoveries, enabling you to build targeted recommenders, identify hidden features, and detect anomalies within your own data.
4.4 (11 Reviews)

Language
- English
Topic
- Machine Learning
Enrollment Count
- 126
Skills You Will Learn
- Clustering, Data Visualization, Machine Learning, Python, Scikit-learn, sklearn
Offered By
- IBMSkillsNetwork
Estimated Effort
- 45 minutes
Platform
- SkillsNetwork
Last Update
- March 17, 2026
About this Guided Project
In this guided project, you will explore clustering algorithms—a core component of machine learning and data science. This project enables you to uncover hidden patterns in data and discover correlations and groups that are not immediately apparent.
Using practical application and theoretical discussion, this project examines algorithms like K-means, hierarchical, and DBSCAN and shows you how to apply them effectively using Python and scikit-learn. You'll build your proficiency in data preprocessing, model evaluation by visualization, and the exploration of real-world use cases such as market segmentation and anomaly detection. When you complete this project, you'll have a solid foundation in clustering techniques and be ready to tackle complex data challenges across various domains.
This hands-on project is based on the Learn clustering algorithms using Python and scikit-learn tutorial.
Using practical application and theoretical discussion, this project examines algorithms like K-means, hierarchical, and DBSCAN and shows you how to apply them effectively using Python and scikit-learn. You'll build your proficiency in data preprocessing, model evaluation by visualization, and the exploration of real-world use cases such as market segmentation and anomaly detection. When you complete this project, you'll have a solid foundation in clustering techniques and be ready to tackle complex data challenges across various domains.
This hands-on project is based on the Learn clustering algorithms using Python and scikit-learn tutorial.
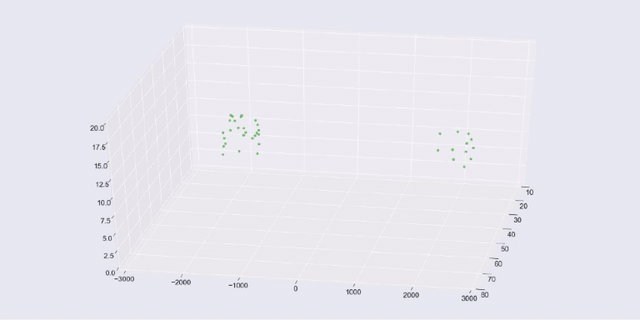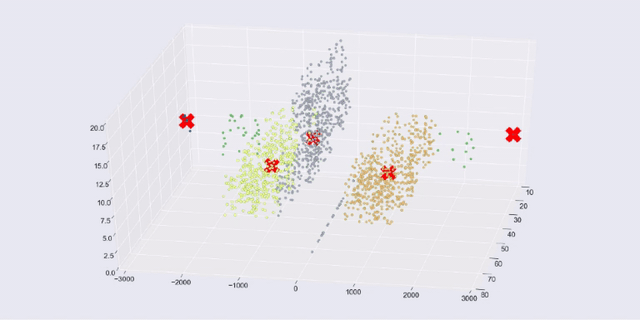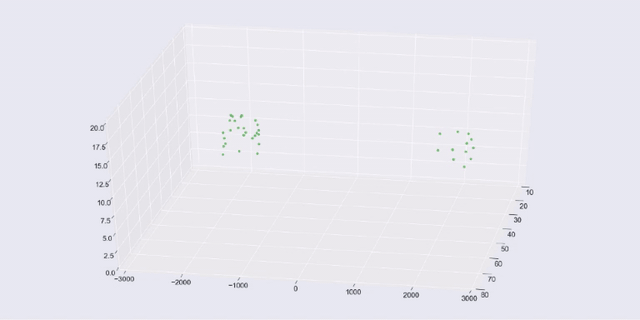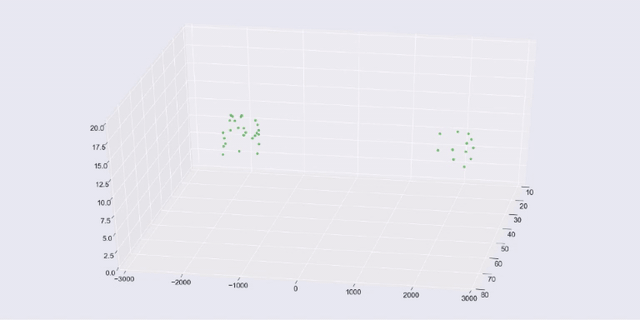
What you'll learn
After you complete the project, you will:
- Understand the fundamentals of clustering algorithms and their application in data science.
- Learn how to implement various clustering algorithms using Python and the scikit-learn library.
- Develop skills in preprocessing data to ensure it is suitable for clustering analysis.
- Gain practical experience in evaluating the performance and effectiveness of different clustering models.
- Explore use cases like market segmentation and anomaly detection to showcase clustering's real-world applications.
What You'll Need
Basic knowledge of Python is required.
Language
- English
Topic
- Machine Learning
Enrollment Count
- 126
Skills You Will Learn
- Clustering, Data Visualization, Machine Learning, Python, Scikit-learn, sklearn
Offered By
- IBMSkillsNetwork
Estimated Effort
- 45 minutes
Platform
- SkillsNetwork
Last Update
- March 17, 2026